A case for effect systems
Daniel Spiewak's 2022 Scala Love keynote. "The" case, but let's dial it back.
- Daniel Spiewak: worked on Cats Effect, scalaz Streams
- works at Disney Streaming
- Examples: Cats Effect, ZIO, Tokio (?)
Archetypical use case: microservice
- Handle request (probably JSON)
2. Decode
3. Scatter to other requests, downstream - Respond
- Encode response
- Gather...
JVM is very good at this pattern. Effect systems lean into this and solve the problems that tend to come with this pattern. One big thing: scarce resources.
Scarce Resources
- Scale is always about managing scarce resources
- CPU
- memory
- file handles
- but also...
- Threads!
- These are only scarce because of how they are implemented
Threads
- You can have ~thousands at most per JVM before things go bad
- Soft limit. Thrashing increases as count rises.
- Often first visible in terms of GC pause times.
- Very slow to allocate. You can't quickly use one, throw it away, and then find another.
- They are our only way to manipulate CPU affinity
- Physical thread counts are extremely low in most cases. Especially true if you use containerization like Kubernetes or ECS.
- Physical thread is like VCPU. it's more than a processor....
- Physical thread is a thread of execution which is entirely parallel when executed with other threads.
- Ideally, each thread maps directly to a single CPU forever. Why?
- Page faults are very expensive. When a single thread is on a CPU, it takes advantage a lot of modern architecture. Every time a kernal evicts a physical thread, the result is usually that the memory pages of the cache get blown away. This is very expensive. Page faults can be 30% of the total runtime in production settings.
- Aligning active thread count to physical thread count is very important.
Imagine we have 2 physical threads / processors and 5 threads in the application space we have to map down to it. The kernal takes care of putting the code onto the processor and the working set into the cache. When a thread is running, it's not like it's just doing math in place with data that's in the registers; it could if you're doing Machine Learning / matric computation, but maybe then you should be using a GPU...
But most realistic threads in a microservices paradigm have a memory state they're working with (values, objects you're carrying, data in the objects you're referencing transitively, etc.). This is the working set of the thread. Anytime a thread takes a step forward in the on the processor, it needs to load that data. It takes care of pulling it through the caching hierarchy of the system.
The caching hierarchy works by making the assumption that, if instruction 1 accesses the piece of memory, then instruction 2 is likely to re-access it or access something near it. All modern hardware design is predicated on this assumption. This generally works very well as long as that thread is sitting there.
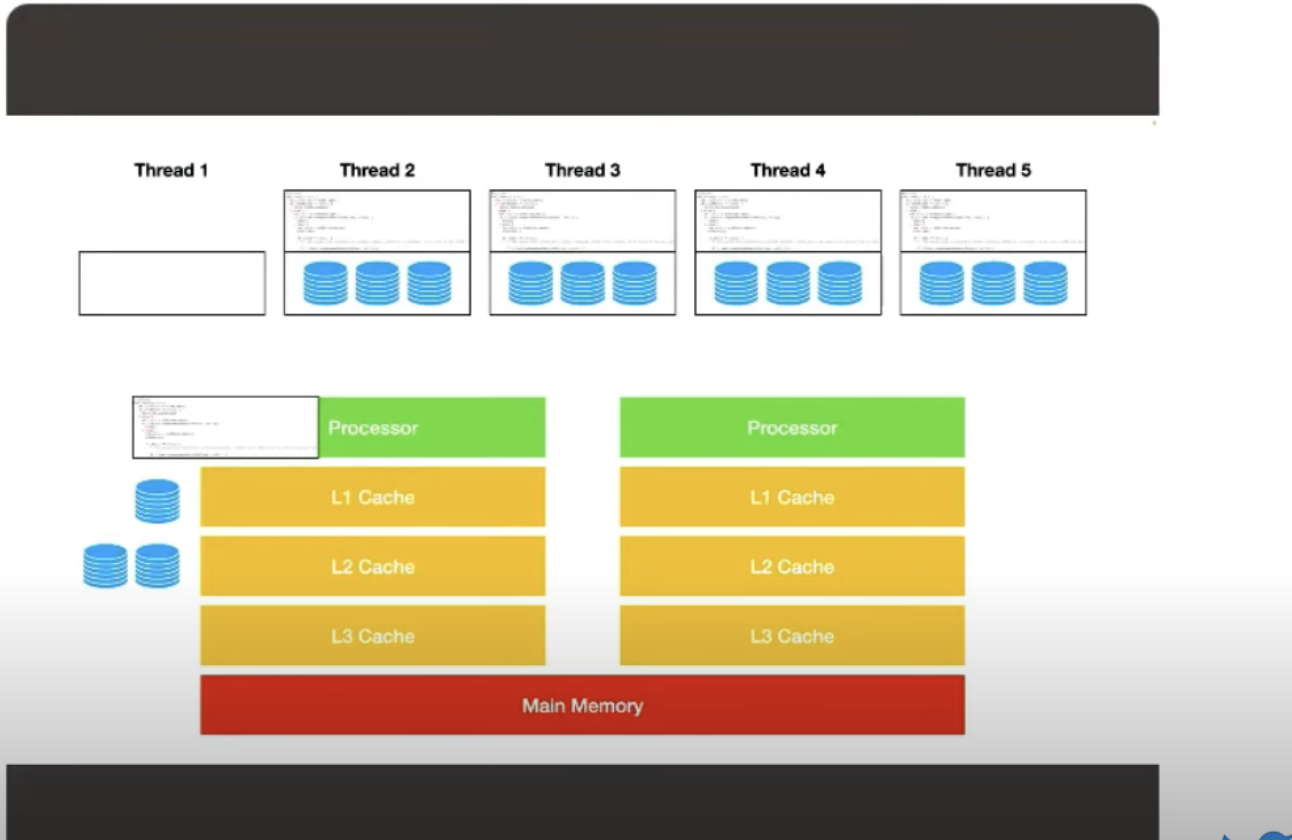
While we're doing this, there may be another thread, say, thread 4, mapped to and running on another processor. Other threads are waiting their turn and suspended by the kernel.
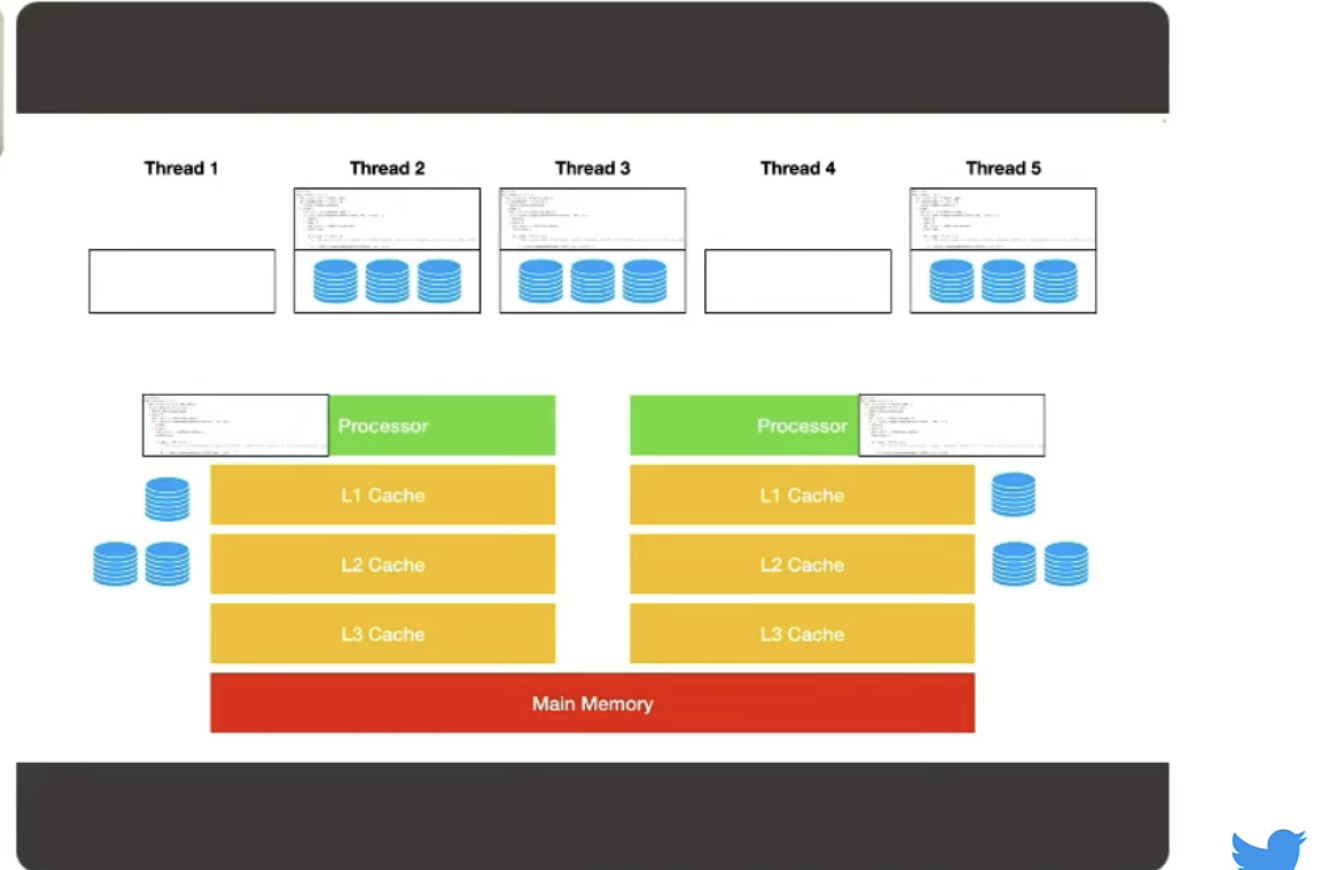
Inevitably what'll happen is the kernel will decide in its scheduler to move one of the other threads onto the processor. When this happens, it'll preempt the running thread and evict it from the core. It'll then effectively waste all the work it did for pulling the memory into the cache hierarchy. Let's say thread 2 gets brought down in put into the processor; the working set for thread 2 has no particular connection to the working set of thread 1. So you'll have a cache miss. It'll need to blow away the caches and then reload from main memory to be useful for thread 2... at least for a little bit. This'll happen again for, say, thread 5, and so on.
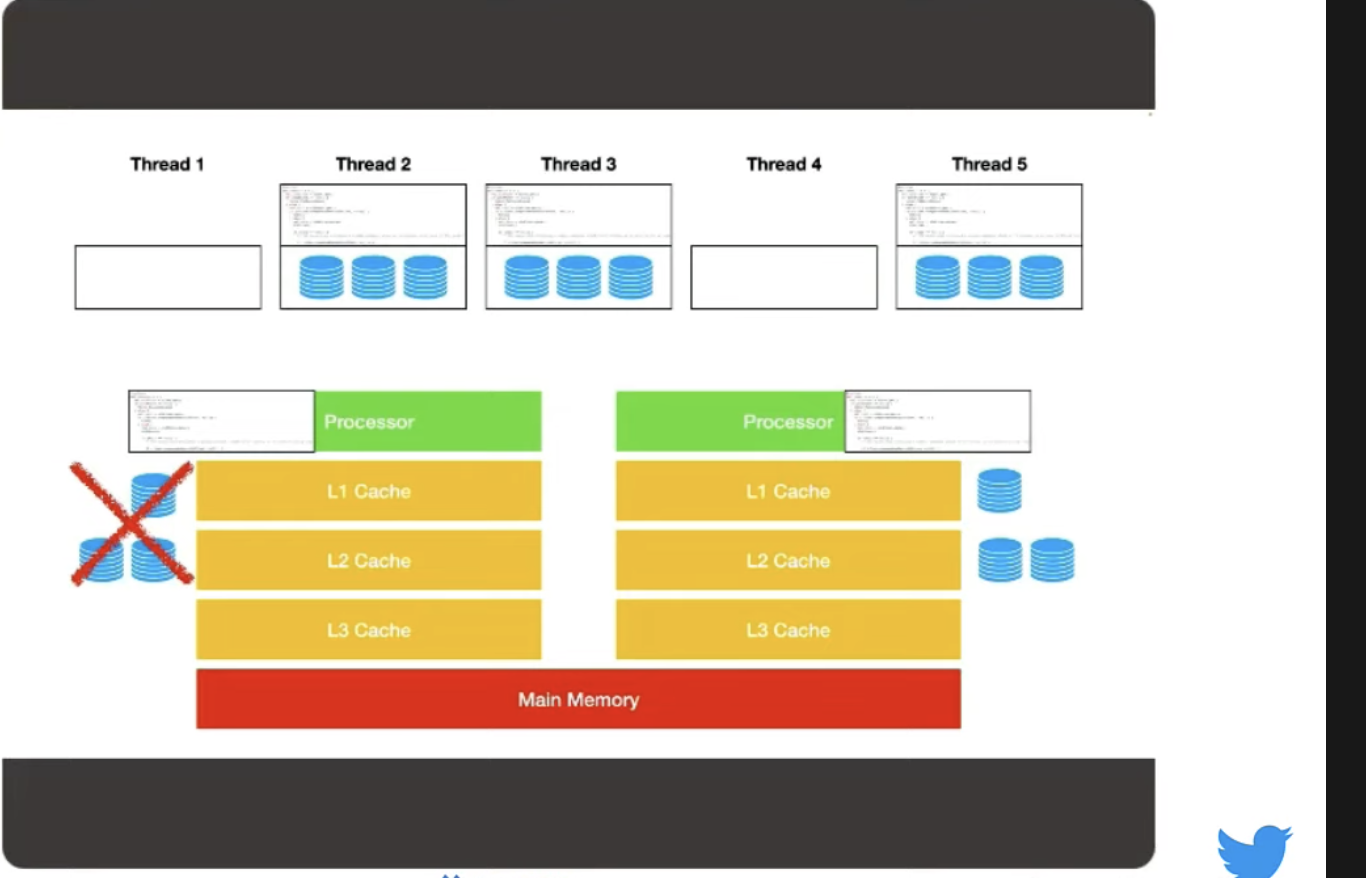
This is why page faults can be so expensive. As thread number incerases, the kernel scheduler is trying to get all these threads onto the physical threads / processors and in so doing evicting other threads. This defeats all the optimizations in the processors. Eventually these cache hierarchies can become a net negative on performance. All optimizations are assumptions, and you're violating these assumptions.
The only way to get yourself out of this scenario is to ensure the kernel scheduler is not trying to jostle threads around between processors. Instead you want an exact mapping between threads you want to use with the underlying processor hardware / physical threads. When that happens, the kernel scheduler will happily keep you defined to a single processor, reducing page faults dramatically and increasing performance.
This idea is behind all the advice I've given in how you map out your threads.
This makes threads an even scarcer resource than we realized -- because of page faults... Instead of 1000-numbers of threads, we should actually reduce to maybe single-digit threads.
However, we have many semantic processes that we are trying to access.
Scaling connections
- Assume 10,000 RPS (target) and 50ms response times
- Average ~500 concurrent connections
- Allocating that number of threads is possible but likely very slow
- Much better to multiplex many connections across few threads
- All systems, at scale, are m:n schedulers.
- Eventually, map connections to threads, threads to processors...
A lot of the space in JVM optimization then revolves around achieving this goal as effectively as possible.
The main way we get there is asychronous processing. Your connections are basically I/O operations, say InputStream. How do you multiplex InputStream?
Asynchronous
- How do you multiplex
InputStream?- read promises to return bytes!
- the calling thread must sit and wait and do nothing else
- Blocking a thread wastes a (very) scarce resource
- particularly bad for scatter/gather workflows!
- If you take the archetype of a request coming in, you can block a thread on that, get the bytes, decode, then make downstream requests to other services... We have to block the same thread again to make those requests.
- If you want to do that in parallel in scatter/gather (common), you actually have to block two threads per incoming request for that paradigm. That's a lot of wasted resources.
- particularly bad for scatter/gather workflows!
- Solution: event loops!
- One thread polls the kernel for all outsstanding I/O events. Not specific ones related to a connection, but everything. Pull them together and batch them up at once.
- If you are another thread that wants to initiate a read or write, you just register that event in the kernel.
- Results are produced using a callback, rather than a return.
- Benefit: threads are free to work on other connections while awaiting results.
- Downside: you need to rewrite your code.
- One thread polls the kernel for all outsstanding I/O events. Not specific ones related to a connection, but everything. Pull them together and batch them up at once.
// before
def foo(): Int = 42
val x: Int = foo() // the flow doesn't continue until you have your Int
// after
def foo() (callback: Int => Unit): Unit = callback(42)
foo() { (x: Int) =>
}
These two expressions are equivalent in terms of expressive power (if you ignore multi-calls) but radically different in terms of how the scheduler can work with them.
Instead of returning an Int, foo() returns a Unit but accepts a callback . This means the thread can register that callback, continue to do other things and call other threads as foo() is getting completed, then goes back to that thread when callback fires to pick up the same semantic action. This is called the CPS Transformation.
This is a paradigm shift: from strictly sequential to semantically sequential. Initially sequence of actions... encoded on a thread, typically with semicolons, statement after statement.
Change to semantic sequentiality. Statement A, at some other point, Statement B. Callbacks still encode "A happens after B", but without throw/return.
Problem: most programs involve a lot of sequential steps and this is really ugly!
foo() { x=>
bar(x) { y =>
baz() { () =
qux(x, y) { z =>
}
}
}
}
So... we want to simplify this with fibers. But we're not quite there yet...
In JavaScript world with NodeJS and then went into Scala, etc....
Promise / Future
Future: a callback that hasn't yet been completed- It is fundamentally about the callback.
- By making it a singular thing that will represent a callback that hasn't yet been completed... that represents the production of this
Avalue... you can take advantage of a lot of things in the ecosystem. In particular...
- Forms a monad, which allows us to flatten out our sequences.
- Insteado of this nesting:
fa.flatMap(_ => fb.flatMap(_ => ...)) - We can do this:
fa.flatMap(_ => ...).flatMap(_ => ...))
- Insteado of this nesting:
- No more callback hell!
// Cleaner!
for {
x <- foo()
y <- bar(x)
_ <- baz()
z <- qux(x, y)
} yield // ...
Now more and more of your code, library, ecosystem... is in this abstraction. This gets painful. Anyone who's worked in a large codebase in Scala especially when other alternatives weren't available at the time makes it hard to debug, test. Do we know if the Future is actually running? Completed? Having a Future of bytes doesn't do much other than let you pattern match.
Simple refactoring can dramatically change program meaning of your code:
val bz = baz()
for {
x <- foo()
y <- bar(x)
_ <- bz
z <- qux(x, y)
} yield // ...
// This is not _necessarily_ the same as the former. `bz` actually runs before `foo()` and `bar(x)`. But it could be the same...
You have to be extra careful when coding, refactoring, maintaining.
You have to be careful about memory leaks. bar() could hold up bz and qux.
No higher-level control flow, just a way of packaging callbacks.
Control Flow
- "This happens before that" is hard to be certain of
- like moving
baz()around - Without knowing everything about the program, you can't be sure, and that's frustrating
- like moving
- Control Flow is a lot more than just sequentialization
- Short circuit with errors
- Good:
Futuredoes this
- Good:
- Timeouts
- Bad:
Futurerequires manual encoding, e.g., shared or atomic boolean flags
- Bad:
- Backpressure must be controlled very explicitly
- backpressure: your system's ability to be elastic while under pressure
- some things will use up their resource limitations faster than others
- Example: depending on upstream services that get delayed because of load, which slows down your processes and you should at that point limit or stop accepting other requests
- If you miss this up, you'll lose the link in the chain. You need to have that "control valve" to propogate a 503 or other things like that back to the client.
- Bad:
Future(s) are handles to results that are being computed (present tense).- You will have to pause the
Futurecomputation, hold it in memory while waiting... "the dam overfills" rather than "river slows down"
- You will have to pause the
- Load shedding must be carefully considered and designed
- Example: Daniel was working on a service that went from 1 million RPS to 100 million RPS. This scaling is wild. There is no way you can recover from this instantly... You need to provision new VMs, for new JVMs to get warm, etc. In the meantime, you need to make sure your app doesn't break. Running out of memory, crashing a system, or worse running out of file handles... is the worst! you'll need to kill a node, etc. to absorb a giant spike.
- This is what Load Shedding is far. You need to stop using scarce resources (not limit using scarce resources).
Futuredoes not help with this at all. It is a fundamentally a push model. I run a computation, invoke a callback that calls aFutureto run.- Backpressure requires the opposite pull model: I am doing a thing, and when I'm ready, I'll ask you to perform your computation and invoke my callback and move forward.
- Short circuit with errors
Evolving Future to... something more
- All the benefits of
Future(wrapping up callbacks) with MORE: - Deterministic control flow
- "A, then B, then C" - make sure this is so even when refactoring
- First-class support for cancellation
- Without this, you cannot implement timeouts for request/response, etc.
- First-class resource management
- Backpressure by default
- I want my system to be safe
- We get load shedding for free
- The service gracefully sheds the load. Clients will get errors, but the system will protect itself by default.
- Memory is managed incrementally out of the box.
Going back to this example, this refactor is fine!
val bz: IO[Unit] = baz()
for {
x <- foo()
y <- bar(x)
_ <- bz
z <- qux(x, y)
} yield // ...
And a more compelling example... retries:
// Retry up to `n` times for any kind of `A`
def retry[A](action: IO[A], n: Int): IO[A] =
if (n <= 0)
action
else
action.handleErrorWith(_ => retry(action, n - 1)
Writing to a file, completing a computation, talking to an upstream service... The semantic of retry can be applied to any I/O action. You cannot do this with Future. Future does not represent an action to be run. It represents a handle to an action which is probably already running. That difference is profound.
I/O represents a handle to an action to be run. You can twiddle with it, run it as many times as you want, not at all, change the way it runs... You can make this more powerful still without peeking into the action. But you actually don't want a retry with n times max to try. You really want one with exponential backoff.
// We have an initial seed, we backoff n times, every time we do with a random value between 0 and current number of milliseconds, we can backoff
def retry[A](action: IO[A], n: Int, backoff: FiniteDuration, rand: Random[IO]): IO[A] = {
if (n <= 0)
action
else
action handleErrorWith { _ =>
rand.betweenLong(0, backoff.toMillis) flatMap { ms =>
IO.sleep(ms.millis) >> retry(action, n - 1, backoff * 2)
}
}
}
Now you can apply this retry with any other action as well.
Let's say you have a 1-second response time SLA:
val makeRequest: IO[Results] = // ...
val withBackoff: IO[Results] =
Random.scalaUtilRandom[IO] flatMap { rand =>
retry(makeRequest, 5, 50.millis, rand)
}
val guarded: IO[Results] = withBackoff.timeout(1.seconds)
There is absolutely nothing in any effect system framework which is hardcoded to these types of cases.... There is no exponential backoff return in Cats Effect. Effect Systems are very general. I can give you many use cases today. What I'm more interested is making sure the use cases 10 years from now can still be applied here.
Resource Management
- Define the actions which open and close a resource
- Glue these actions together such that you'll always close the resource...even in timeout and error cases!
- Separate your logic which constructs the resource from how it is used. Remove coupling across lifecycles
def connect(uri: String): Resource[IO, Connection] =
Resource.make(openConnection(uri))(conn -> conn.close)
// meanwhile, elsewhere
for {
conn <- connect("jdbc:postgres: ...")
cursor <- Resource.eval(conn.execute("SELECT * FROM users"))
// ..
cursor2 <- Resource.eval(conn.execute("UPDATE users SET name = ? WHERE id = ?"))
// ...
} yield ()
Resource is another monad on top of I/O that lets us talk about resources as a thing that may have an unbounded scope. As long as we connect in the way we do above, we can keep adding semantics... and so at the end of that connection, it will be closed without us even thinking about it.
Let's say we have 2 replicas and we want to connect to both of them at the same time, but discard the slower one:
val uri1 = "jdbc:postgres:replica1"
val uri2 = "jdbc:postgres:replica2"
val joint: Resource[IO, Connection] =
connect(uri1).race(connect(uri2)).map(_.merge)
Ecosystem
- Small and composable functional surface area
- Reliable foundation on which to build complex functionality
retry- Streaming
- Web frameworks
- Redis clients, Postgres clients, etc...
- So much you can do when you can trust the layers below.
- Safely layer additional functionality on top of lower-level pieces.
Next Generation Reactive
- Moves the state of the art signficantly beyond callbacks and coroutines
- Initiatives like Project Loom obsolete
Future, but notIO- Loom gives you a solution for coroutines and abstract flows, but nothing for resources, timeouts, preemptions, mechanisms for control flow
- Sets the guardrails for safer, more composable applications and libraries
- Constrains the problem space to allow for deeper integration
Deep Runtime Integration
- algebraic model allows more complete insight into programs
- Declarative blocking (and interruptible) regions control starvation cases
- this means the runtime can understand things better and optimize around it
- Work-stealing fiber runtime with aggressive physical thread affinity
- when we were talking about CPUs, cache affinity, page faults... we put forward the claim that page faults are expensive and need to explicitly map threads to physical threads / processors to avoid them.
- We can map threads to CPUs, and we can go further and map fibers to processors. Fibers are semantically the same idea as a thread -- each step will use about the same memory as the previous step. Fiber = single request/response type thing.
- Page faults drop very very low.
- When you look at the scheduler, 1-2 orders of magnitude faster than a handwritten conventional disrupter pattern.
- Cooperative polling on timers (WIP targeted at Cats Effect 3.4)
TestControl- get into runtime and change way the program is going to execute without changing the program itself
// munit
test("retry at least 3 times until success") {
case object TestException extends RuntimeException
var attempts = 0
val action = IO {
attempts += 1
if (attempts != 3) throw TestException
else "success!"
}
val program = Random.scalaUtilRandom[IO] flatMap { random =>
retry(action, 5, 1.minute, random) // runs in a few milliseconds
}
TestControl.executeEmbed(program).assertEquals("success!")
}
// can introspect the runtime
Performance Proven at Scale
- Deployed by some of the largest companies in the world
- Tokio sponsored by Amazon
- Numerous "household name" services powered by effect systems
- Disney Streaming
- Assumption: number of IO allocations is linearly proportional
O(k n)to I/O- Aka your application is I/O bound
- The allocation overhead is demonstrably irrelevvant in these cases
- FP "in the large", rather than FP "in the small"
Constraints
- Wrap all side effects in
delay,async,blocking, orinterruptible, whatever is most appropriate - Use
bracketorResourcefor anything which must be closed- Gives you composability of resources
- Never block a thread outside of
blockingorinterruptible- Your runtime will be very good
- Use
IOAppinstead of writing your owndef main- gives you the next bulletpoint for free
- Never call anything that has the word
unsafein the name
Conclusion
- Effect systems are an extremely well-motivated evolution
- Project Loom replaces
Future, not IO - Performance is excellent
- In practice, often better than hand-rolled alternatives
- ...even with excess allocations
- Foundation for a lqyered and powerful ecosystem