Notes: 'Your Search Service as a Composable Function'
From former Etsian Stefanie Schirmer in 2018 on designing Etsy's search platform using Finatra and functional programming principles.
Because Etsy has a lot of unique, handmade and vintage items not normally found on other ecommerce sites, we have a unique challenge when it comes to building an effective search engine.
Etsyweb is built with PHP. Originally we had no search; it was just a directory of quirky items. It was hard for people to find anything. Eventually we added Solr as part of a Java backend search for the listings (items to buy) that the PHP layer could query. We then added indices for people (users), messaging, and other features. We split the taxonomy between buyers and sellers. At this point we had some indices in Solr and some in Elasticsearch. We also had a read-only key-value store to unify features between Redis datasets and in-house solution called Arizona. We made this unification to be very fast.
Search Query Pipeline
A few challenges. Typical scalability, availability concerns. And then also, how to incorporate machine learning?
We had ranking with extended file fields that were trained on a nightly Hadoop job. These jobs delayed the ability for us to react to real time data and include context-speciifc data with our queries. The context keeps changing in Etsy because we have a lot of changing trends. For example, at some point slime was a very popular search for kids' toys. So we really needed real-time inference. How can we improve our architecture to do this? With the right abstractions, this should be easy, right?
Mixer, MMX
We found the MiXER written in Java. We changed how we did the configs, Thrift, etc. It was not very modular.We acquired Etsy's Blackbird Project. We switched to Scala to take advantage of the Twitter stack and functional programming for reusable code. We called it the Merlin Mixer or MMX.
The Twitter stack uses Finagle which is a protocol-agnostic RPC framework that provides (something) monitoring and load balancing.
"Your server as a function" paper. Your entire server is a function -- we know what comes in and goes out without side effects. We expect a Thrift request and return a Future[(Thrift) Response]. Now we needed to rewrite our search Query and response. For example,
- for requests: spell correction and normalization, adding context, related searches
- for response: we want to rerank what we get from the search index, for example, using a machine learning model.
To scale and make it easy to reason about, we want to minimize mutable state. We use configs to modify requests so we know the state of what's coming in.
Finagle's Futures let us asynchronously model the requests without needing to worry about the individual effects. Scala's type system lets us write service code in an abstract way so we can say this code is protocol-agnostic. We can pretend what we would do with the response even if we don't have it yet. Similar to Java Futures but with Scala and Twitter Futures we can flatMap.
Service with filter
import com.twitter.finagle.Service
import com.twitter.finagle.Http
val service: Service[http.Request, http.Response] = ...
val timeoutFilter = new TimeoutFilter[http.Request, http.Response](...)
val serviceWithTimeout: Service[http.Request, http.Response] = timeoutFilter.andThen(service) A Finagle Service
case class ArizonaService (...) extends Service[ArizonaRequest, ArizonaResponse] {
def apply(req: ArizonaRequest): Future[ArizonaResponse] = {
req match {
case MultiGet(..., keys) if keys.size > Keys.MaxSize =>
// fail
case _ =>
// find client for shard
// set request headers
client(r).map { resp =>
makeResponse(req, resp)
}
}
}
} flatMapping Futures
Lets us easily and safely compose asynchronous calls to be synchronous when we want.
Reader Monad
Used when we want to keep some information throughout calls where that information doesn't change. There is an implicit read-only concept.
A Merlin Mixer Service
We now have a Req => ReaderToFuture[Ctx, Rep] which looks odd. It is a ReaderMonad with FutureMonad. It reads a type of Ctx context and returns a Rep response. It is a Monad Transformer that has a side effect of reading the context and transforms the response into a Future.
type ReaderToFuture[Req, Rep] = ReaderT[Future, Req, Rep]
object ReaderToFuture extends KleisliInstances {
def apply[Req, Rep](f: Req => Future[Rep]): ReaderToFuture[Req, Rep] => Kleisli.kleisli(f) // we always want a Future type and be able to flatMap with other Rtfs
}
implicit object FutureMonad extends Monad[Future] {
def point[A](a: => A): Future[A] = Future.value(a)
def bind[A, B](fa: Future[A])(f: A => Future[B]): Future[B] = fa.flatMap(f)
}
It's a proxy!
ThriftReq => ReaderToFuture[Ctx, ThriftRep]
Example: Query pipeline
What is a service?
Example: Spell Correction Service
- get "hand baag" search query
- go to spell correction service
- correct query to be "hand bag"
Then, with sequential + concurrent calls
- Get query
- Send it to orchestration service
- Orchestration service calls multiple transformer services like Spell Correction at once (concurrently)
- These services call another single service, or whatever (sequentially)
- Eventually we get a corrected, combined query
Our components
Data
Search indexes
- Solr
- Elasticsearch
Feature and candidate stores
- Arizona -> Key-Value store
- BigTable / DynamoDb
- MySQL
Cached model output
- Memcached
- Redis
Service
Machine Learning Models
- hosted on a separate service
- engine agnostic: Vowpal Wabbit or Tensorflow or Pytorch?
- Json Input -> Output over HTTP
- Send batch calls with features -> get back scores
- Finagle: send parallel batches to multiple instances. If too slow, can add more machines (scalable). Can make larger models or run them on larger candidate sets.
External APIs
Any cloud provider with ML APIs
- Azure ML, Google Cloud ML, Amazon ML)
Notes:
- Vowpal Wabbit is an online ML traning model library.
- Tensorflow is a neural networking streaming library from Google.
- Pytorch which is another NN streaming library.
Models as a service
Inference in real time
- No precomputed score values -> No fixed domain
- Separate update schedules for model and feature stores
- Important at Etsy: context keeps changing, which is generated by users.
Each model scales independently
- Allows sub-models to be more expensive
- Each model is versioned so we can experiment on them and compare
- We can have models that scale in different ways depending on need (computational expense)
- Each data source is independent
Ensemble over models in real time
- Each model gets updated independently
- Combining function can be a model itself
- Can define failure scenarios for partial failure. If first model has a wrong prediction, etc., we can clearly define what should be fixed.
Before and after
Before
- Web stack talks to our key-value store (Arizona)
- Web stack constructs web query
- Web stack sends query to mixer
- Mixer has a lot of state, all the search logic. Query is being mutated a lot.
- Mixer executes the mutated query on the shards.
- Mixer combines the results.
- Mixer returns results to the web.
Mixer and Solr shards are running on a Solr server. Solr shards are running plain Solr. Mixer is running a custom version of Solr that can do the fan-out through the shards. Worked and scaled well with query-based weights on the listings for awhile.
Still, we weren't ranking and querying as many listings as we liked. All of the state in the mixer was hard to work with. All the querying, ranking, and boosting weights were in the mixer. It would be better to store all those weights in the configs and change them dynamically.
- Java / PHP
- Models tightly coupled to search code with mutated state
- Query being mutated and then "executed"
- Cost of change is high
- Bound by synchronization
- Hard to distribute load and computation
- Search results not great
After
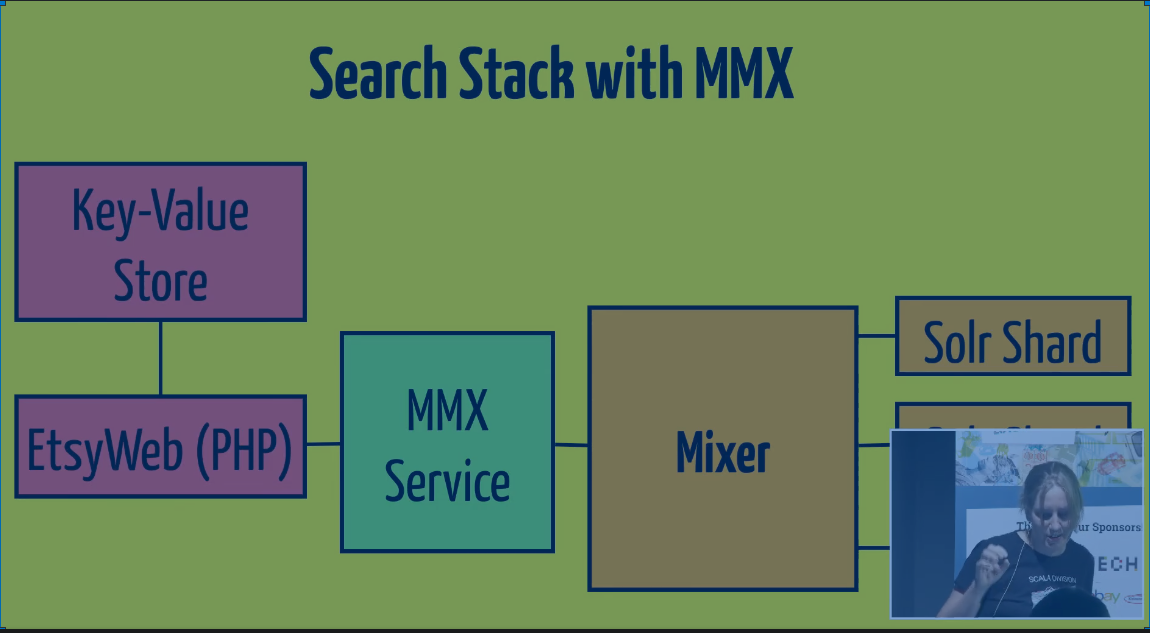
With MMX, we intercepted the search pipeline between the Web and the Mixer. Before the query hits the search index, it hits the MMX service. MMX then hits the mixer (?) with the same Thrift interface.
- Scala/Finagle/Finatra
- Models as a service, scale independently, versioned
- Real time inference pipelines
- Build a query plan with ReaderToFuture
- Helps us debug and predict query
- Makes code match cleaner
- Async communication with sub-services
- Search results make more sense! MMX + Query Ranking
State woven into one service -> Service DAG
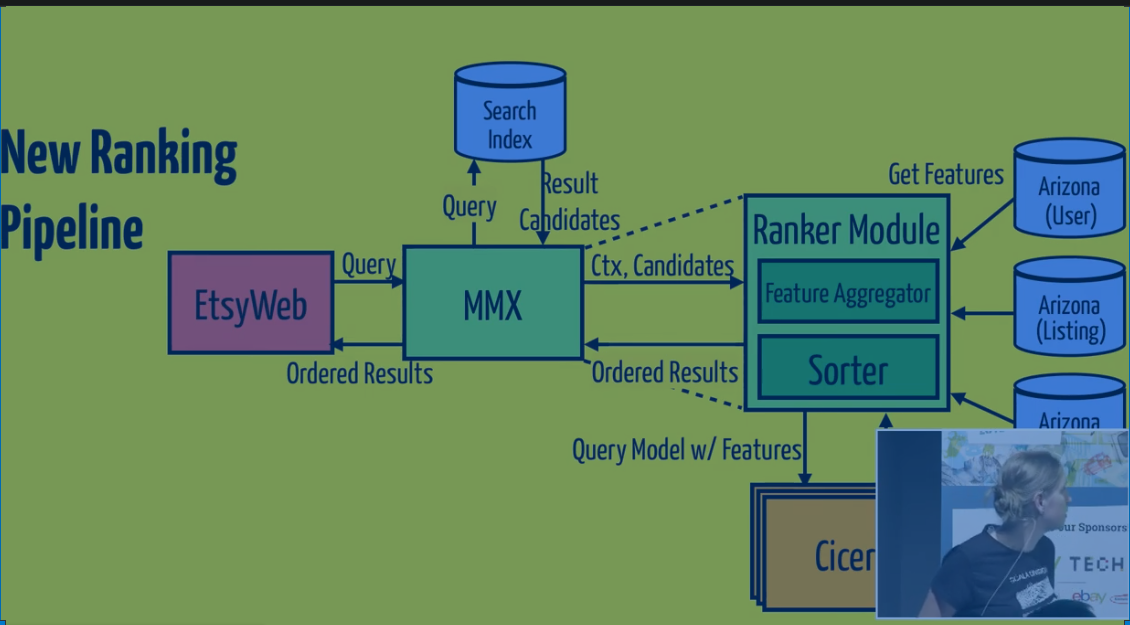
- Query from Etsyweb
- Query to MMX
- MMX query to Search Index
- Search Index returns result candidates
- MMX sends context, candidates to Ranker Module, which gets features from Arizona feature store (title of listing, seller, buyer, reviews)
- Construct features + query as a payload to hit our ranking model
- The service that provides these models is Cicero, which is on Kubernetes
- Fan out to 1000 listings, can do in batches, easy in Scala
- Sort them in Ranker Module
- Send back ordered results in MMX
- MMX filters out results based on Etsyweb pagination (which page, number of results, etc.)
What do we do with a peculiar query?
"kanye west sneakers for puppies" - no items, so instead we show alternative choices. Called "backoff" to back off to alternative queries.
How do we use MMX to construct candidates and query?
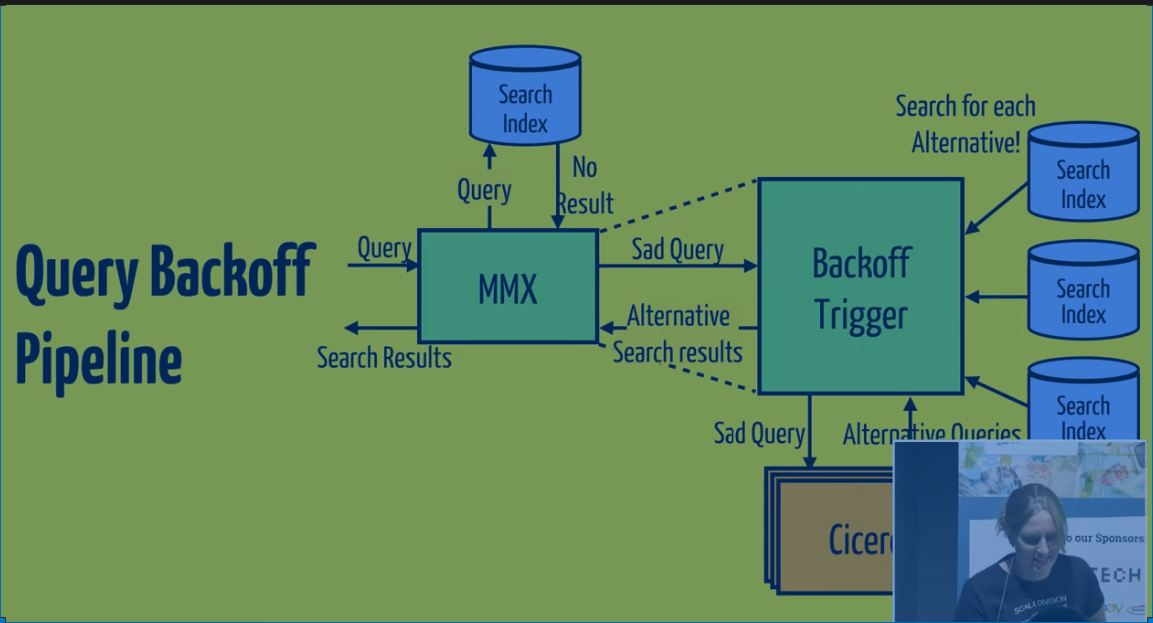
MMX figures what gives us valid search results.
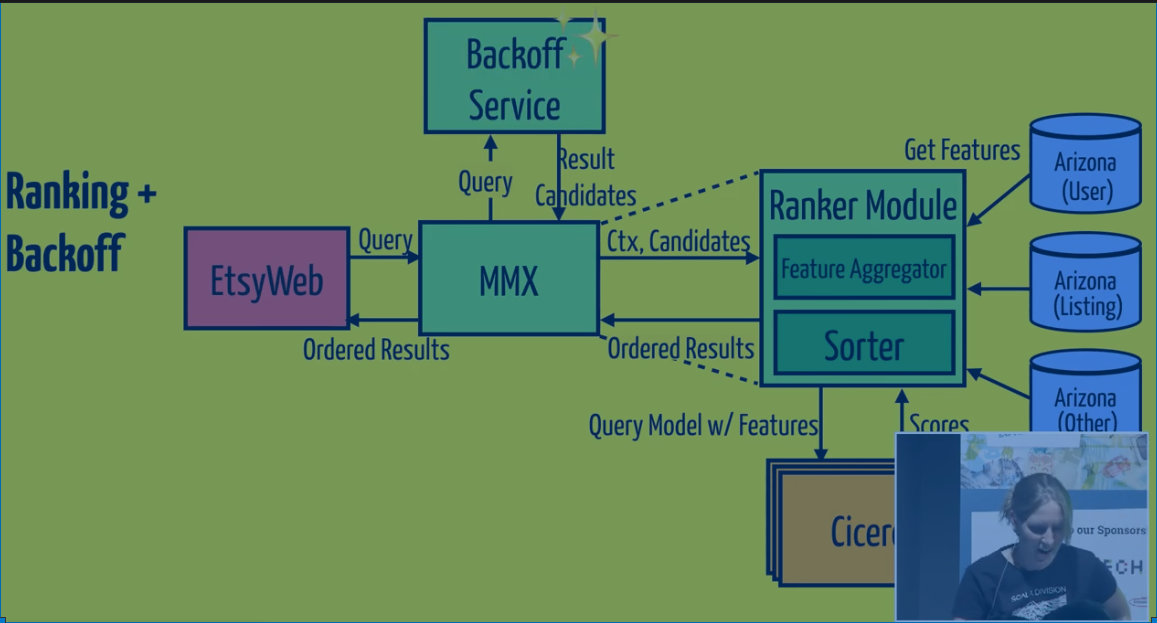
In the code we just switch out a function call from index to backoff service.
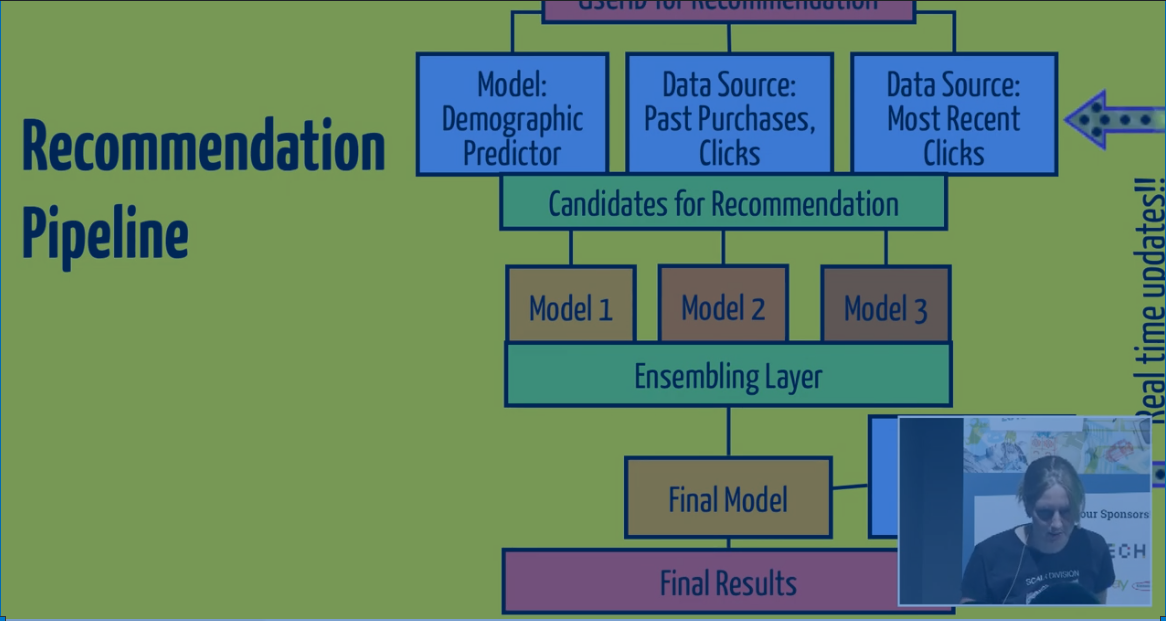
We concurrently hit 3 areas -- the demographic predicter model, the past purchases and clicks source, and the most recent clicks source. Let's say we have the top 500 probable listings for a user. from those models. We then concurrently hit 3 models. You can combine the score...
MMX lets us build pipelines like this quickly. Principles for each pipeline are the same.
A/B Testing
Configurable pipelines -> Create versions of a pipeline
- different model versions
- different arguments to services
- Example: increasing reranking coverage was only a config knob switch
- different data sources -> features, candidates, etc.
- pick and choose datasets, versions
We use HOCON format (human optimized config option notation). For human-readable data, like JSON. You can use variables in it.
Here is a configuration control. It's ranking 200 listings, or 400 listings, etc. Or we want to do manual scoring. YOu can map them through different distributions in the config file.
Takeaways
- Each service is a reusable unit in the query DAG
- algebra over services
- models as a service -> real time inference
- building new ML query pipelines is fun! + we can debug and experiment
- towards query understanding!